

인공지능 영상인식 기반의 정보보호 및 보안 솔루션을 제공합니다.
Tech & Market
LLM, AI 전환을 가속하는 동력기
효과적인 AI 전환을 위해서는 위한 하드웨어, 소프트웨어 등의 광범위한 인프라와 제도적, 윤리적 기반이 마련돼야 합니다. 그리고 중요한 기술적 요소로 LLM이 꼽히는데요. LLM는 단순히 AI 기술 중 하나라기보다 AI 전환을 가속하는 핵심 동력에 가깝습니다.

우선 LLM은 AI 전환의 촉매제로서 ‘특정 업무의 자동화’ 수준을 넘어, 지식·언어 기반 모든 프로세스에 적용될 수 있습니다. 기존의 IT 시스템과 사람이 하던 업무의 범용적 자동화를 가능케 하며, 이를 통한 AI 전환은 부분적·부문별 AI 도입이 아니라 조직 전반의 변화로 이어집니다.
이를 통해 LLM은 공공 및 민간의 AI 확산을 가속화하는 데 기여하고 있습니다. 공공 부문에서는 행정문서 요약, 민원 응대, 다국어 번역 등에서 빠르게 확산 중입니다. 특히 LLM 기술의 비약적 발전은 ‘AI 도입을 검토하는 초기 실험 단계’를 건너뛰고 곧장 ‘대규모 AI 확산 단계’로 AI 전환을 가속화할 수 있는 토대가 되고 있습니다. 민간 영역에서는 금융, 제조, 유통, 콘텐츠 산업 등에서 생산성과 의사결정의 효율성을 높이고 고객 경험을 개선하는 데 LLM이 기여하고 있으며, 새로운 비즈니스 모델과 서비스를 창출하는 동력이 되고 있습니다.

국가적 차원에서도 LLM 기술은 AI 주권(sovereign AI)을 확립하는 데 핵심적인 무기가 됩니다. 우리나라는 HyperCLOVA X(네이버), KoGPT(카카오브레인), EXAONE(LG) 등 혁신 LLM을 통해 글로벌 빅테크 의존도를 낮추고 AI 주권 확립을 실현하고 있습니다.
시선AI는 LLM 기반의 에이전틱 AI(Agentic AI) 플랫폼 종합 솔루션 전문 ‘디윅스’, 네이버의 초거대 AI 모델 HyperCLOVA X 기반으로 특화모델 개발 및 다양한 AI 사업을 전개하고 있는 ‘클라비’ 등 우수한 LLM 역량을 보유한 기업들과의 기술 협력을 통해 AX 사업화 및 멀티모달 AI 기술 고도화에 매진하고 있습니다.
VLM, AI 전환을 확장하는 증폭기
LLM을 언어 중심의 AI 전환 엔진으로 본다면, VLM은 멀티모달 AI 전환의 관문으로서 더 큰 확장성을 제공합니다. 즉 LLM이 언어·텍스트 기반의 AI 전환을 열었다면, VLM은 이미지·영상·텍스트가 융합된 멀티모달 AI 전환을 가속합니다. 사람의 의사소통에는 언어뿐 아니라 시각이나 청각의 요소까지 포함돼있듯, 멀티모달 AI는 현실 세계와 AI를 연결하는 폭을 넓히는 역할을 합니다.

공공 서비스 부문에서는 ▲서류(스캔 이미지)와 텍스트를 함께 이해하는 AI 민원 처리 ▲이미지 기반의 문제 풀이가 가능한 AI 기반 교육 솔루션 ▲시각장애인을 위한 복지 정책 및 시스템 구현 ▲공공·교통 시설에 대한 안전 관리 및 재난 대응 등에 활용될 수 있습니다. 공공 부문에서 VLM은 포용적 AI 전환의 핵심 기술이 됩니다.
산업 현장 등 민간 영역에서는 ▲관제 및 리포팅을 통한 보안 ▲비전 검사를 통한 불량 검출 ▲유통·물류 현장의 재고 관리 ▲근로 현장의 안전 관리 ▲의료 분야의 영상 판독 및 진단 등에 활용될 수 있도록 VLM 기술 개발 및 상용화가 활발하게 전개되며, 시각적 데이터를 언어로 해석·설명함으로써 현업 업무의 언어화(Documentation)를 자동화하고 있습니다.

VLM은 현실 세계를 AI로 옮겨오는 창(Interface)입니다. 국가 차원에서는 국방, 의료, 치안, 재난 관리 등 현실 세계 데이터를 처리하고, 조직 차원에서는 텍스트 중심의 LLM 협업 단계를 지나 ‘시각+언어’ 공동 작업 환경을 열고 있습니다. 따라서 VLM은 AI 전환의 의미를 ‘조직 내부 지식 전환’에서 ‘현실 세계와 연결된 전환’으로 확장시키는 차세대 핵심 동력이 될 것입니다.
VLA, AI 전환을 구현하는 변환기
많은 AI 기술이 물리적 공간으로 확장하고 있습니다. 즉 ‘피지컬 AI’ 시대를 열어가고 있는 것입니다. 로봇 기술 관련 주요 전시회 및 컨퍼런스 등에서는 ‘지능형 로봇과 인간의 공존’이 주요 주제로 부상했으며, 로봇, AI, 보안 등이 함께 주목받고 있습니다. 국내 기업들의 오픈 생태계 구축 움직임도 활발해지고 있다는 평가입니다.

앞서 언급한 LLM 및 VLM 기술이 필수 요소로서 빠르게 발전하고 있으며, 이를 탑재한 로봇은 인간이 입력한 자연어 명령에 스스로 인지한 시각 정보를 결합해 필요한 행동을 판단하고 출력하게 됩니다. 이른바 VLA(Vision‑Language‑Action) 기술이 구현되면서, 로봇이 듣고 보고 판단해 움직이며 AI를 현실에 구현하는 실제적 엔진으로 작동하게 됩니다.
LLM, VLM 및 VLA 기술은 비전 AI 로봇 산업에 혁신을 가져올 것으로 기대됩니다. 산업 현장에서는 로봇의 프로그래밍을 다시 할 필요가 없이 로봇이 스스로 작업 전환을 수행하게 되며, 멀티모달 언어 명령을 이해하면서 작업 범위도 더욱 늘어날 전망입니다. 즉, 로봇이 ‘눈’을 가지면 자율성과 유연성이 강화됩니다.

시선AI는 로봇 전문 자회사 유온로보틱스를 통해 피지컬 AI 기술력을 강화하고 있습니다. 자사의 비전 AI 기술과 유온로보틱스의 로봇 개발 기술을 융합함으로써 비전 AI 로봇 기술을 고도화하는 데 매진하고 있습니다.
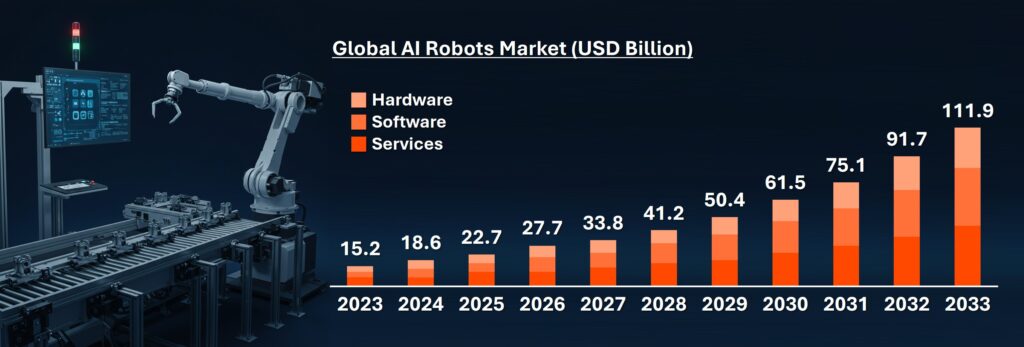
시장 조사 기관 Market.us에 따르면 글로벌 AI 로봇 시장은 2023년 약 152억 달러에서 연평균 성장률 22.1%를 기록하며 2033년까지 약 1119억 달러 규모에 이를 것으로 예측됩니다. 또한 Markets and Markets는 로봇 비전 시장이 2025년 약 33억 달러에서 2030년 약 50억 달러 규모로 성장할 것으로 내다봤습니다.
[전문 목차(링크)]